
미니 SemiAnalysis & Locuza, Nvidia Ada Lovelace 예측
- 좌지우건
- 조회 수 387
- 2022.04.16. 12:35
SemiAnalysis & Locuza가 지난 Nvidia 해킹으로 유출 되었던 Ada Lovelace 시리즈에 대한 예측분석을 하였습니다.
- Ada Lovelace 유출
https://meeco.kr/mini/34750268
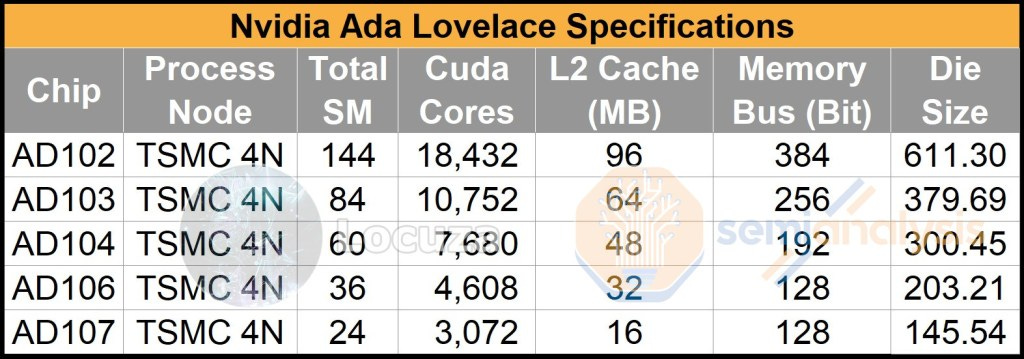
스펙은 이미 많이 알려져 있고
Die Size 예측이 추가되었는데...
AD102를 예로 예측과정을보면
우선 GA102 다이샷과 AD102 유출 스펙을 기반으로
GA102 아키텍처를 사용 시의 AD102와 동등스펙의 다이 구성을 합니다.

그러면 1629.60mm2의 크기의 어마어마한 다이가 나오는데...
여기서 단순히 공정변경만을 반영해서 다이사이즈를 예측하는 것은 너무 불합리합니다.
예시로 위 이미지에서도 확인할 수 있듯 단순히 유출 스펙에 맞추기만해도 L2캐시 영역이 너무 어마어마하게 커지게 됩니다.
이러한 불합리를 개선하기 위해 캐시설계의 변경 같은 요소를 적용합니다.
- SRAM 설계 및 공정차이에 따른 Die Size
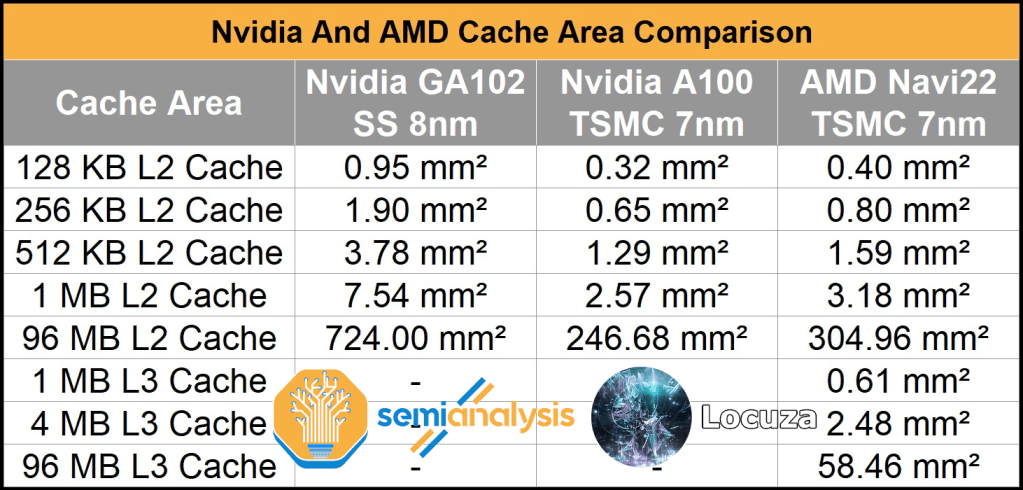
예를 들어 GA102는 64-bit memory controller / frame buffer partition (FBP) 당 1MB of L2와 함께 48, 128KB slices of SRAM를 사용하는 반면
GA100 는 80 512KB slices of SRAM를 사용하고
이러한 larger slices 사용은 density 상향을 가져옵니다.
유출에서 AD102는 FBP에서 64-bit memory controller 당 16MB of L2를 사용함을 알 수 있고
Nvidia는 48, 2048KB slices of SRAM를 사용하는 쪽으로 갔다고 예측됩니다.
이외 다른 IP블락들에서도 비슷한 작업을 하고
공정변화 (삼성 8N > TSMC 4N)를 적용하여 Die Size를 예측 하였다고합니다.
추가로 흥미로운 내용은 수율 이야기인데...
The density increase from a TSMC N4 derivative is quite large relative to a Samsung’s 8nm derivative, which justifies the cost. Interestingly despite being a much newer node, SemiAnalysis sources report that TSMC N4 actually has a slightly better parametric yield than Samsung’s 8nm node despite similar catastrophic yields. This is mostly a non-issue for GPUs as nearly every die can be yield harvested.
네 TSMC N4가 삼성 8nm보다 수율이 더 잘나온다고 합니다.





막줄이 충격이네요..